热点-“世界模型”大争议:杨立昆狠批Sora不是世界模型,生成式路线注定失败
过去一周,Sora 的光芒有多耀眼,谷歌与 Meta 就有多落寞。
就在 Sora 发布的同一天,另有两款重磅产品推出:一是谷歌发布支持 100 万 tokens 上下文的大模型 Gemini 1.5 Pro;二是 Meta 发布“能够以人类的理解方式看世界”的视频联合嵌入预测架构 V-JEPA(Video Joint Embedding Predictive Architecture)。
只是由于发布日期与 Sora “撞车”,与它们有关的消息基本都被埋在了铺天盖地的 Sora 新闻流里。可以说在话题热度这块儿,Gemini 1.5 Pro 和 V-JEPA 被 Sora 杀得片甲不留。
如果说作为语言模型的 Gemini 1.5 Pro 与 Sora 还不在同维度竞争的话,与 Sora 同属视频生成模型的 V-JEPA 便是“实惨”了,发布的前两天基本无人问津,甚至连业内都很少关注到。
Sora 之所以引发了全世界的关注,不仅仅在于它是一个高质量的视频生成模型,更在于 OpenAI 把它定义为一个“世界模拟器”(world simulators)。
OpenAI 表示:“ Sora 是能够理解和模拟现实世界模型的基础,我们相信这种能力将成为实现 AGI 的重要里程碑。”
英伟达高级研究科学家 Jim Fan 更是直接断言,“Sora 是一个数据驱动的物理引擎,是一个可学习的模拟器,或世界模型”。
Sora 是世界模型?这让图灵奖获得者、Meta 首席科学家 Yann LeCun(杨立昆)坐不住了,LeCun 多次在社交平台 X 上“狠批” Sora,表示 Sora 的生成式技术路线注定失败。
LeCun 显然出离地愤怒:“我从未预料到,看到那么多从未对人工智能或机器学习做出任何贡献的人,其中一些人在达克效应(Dunning-Kruger effect)上已经走得很远,却告诉我我在人工智能和机器学习方面是错误、愚蠢、盲目、无知、误导、嫉妒、偏见、脱节的......”
Yann LeCun的X截图
这场关于世界模型的巨大争议,到底是如何发生的?
01 OpenAI的生成式路线,大佬们怎么看?
目前,几乎所有的深度学习模型都是建立在 Transformer 架构上。但是在追求通用人工智能(AGI)的道路上,存在不同的流派。
OpenAI 是自回归生成式路线(Auto-regressive models),遵循“大数据、大模型、大算力”的暴力美学路线。从 ChatGPT 到 Sora,都是这一思路的代表性产物。
简而言之,Sora 通过分析视频来捕捉现实世界的动态变化,并利用计算机视觉技术重现这些变化,创造新的视觉内容。它的学习不限于视频的画面和像素,还包括视频中展示的物理规律。
Sora 采用了以 Transformer 为骨架的 Diffusion Model(扩散模型),其拔群的效果也验证了扩展法则(scaling law)与智能涌现(Emergent)依旧成立。
值得一提的是,OpenAI 把 Scale 作为核心价值观之一:我们相信规模——在我们的模型、系统、自身、过程以及抱负中——具有魔力。当有疑问时,就扩大规模。
但是,LeCun 却认为“自回归生成模型弱爆了(Auto-Regressive Generative Models suck)”!
他认为,自回归路径是无法通往 AGI 的。LeCun 本人不止一次公开表达了对自回归生成模型热潮的批评:“从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。”
2 月 13 日,在 2024 年世界政府峰会(World Government Summit)上,LeCun 就谈到“他并不看好生成式技术”。他认为“文本处理的方法无法直接应用于视频”,并顺水推舟地宣传一下自家研究,“目前为止,唯一看起来可能适用于视频的技术,是我们研发的 JEPA 架构”。
几天后,他再次“狠批” Sora,仅根据文字提示生成逼真的视频,并不代表模型理解了物理世界。LeCun 表示:“生成视频的过程与基于世界模型的因果预测完全不同”;2 月 19 日,他又一次发文驳斥道:通过生成像素来对世界进行建模是一种浪费,就像那些被广泛抛弃的“通过合成来分析”的想法一样,注定会失败。
LeCun 认为文本生成之所以可行,是因为文本本身是离散的,有着有限数量的符号。在这种情况下,处理预测中的不确定性相对容易。在高维连续的感觉输入中处理预测不确定性基本上是不可能的。“这就是为什么针对感输入的生成模型注定会失败的原因”。
在不看好 Sora 技术路径的质疑声中,不只有 LeCun。
Keras 之父 François Chollet 也持有相似观点。他认为仅仅通过让 AI 观看视频是无法完全学习到世界模型的。尽管像 Sora 这样的视频生成模型确实融入了物理模型,问题在于这些模型的准确性及其泛化能力——即它们是否能够适应新的、非训练数据插值的情况。
François Chollet的X截图
Chollet 强调,这些问题至关重要。因为它们决定了生成图像的应用范围——是仅限于媒体生产,还是用作现实世界的可靠模拟。
同时他还指出,仅仅依靠拟合大量数据(例如通过游戏引擎生成的图像或视频)来期待构建出能广泛适用于现实世界所有情况的模型是不现实的。原因在于,现实世界的复杂度和多样性远远超出了任何模型通过有限数据所能学习到的范围。
Artificial Intuition 作者 Carlos E. Perez 则认为 Sora 并不是学会了物理规律,“只是看起来像学会了,就像几年的烟雾模拟一样。 ”
Carlos E. Perez的X截图
知名 AI 学者、Meta AI 研究科学家田渊栋也表示,关于 Sora 是否有潜力学到精确物理(当然现在还没有)的本质在是:为什么像“预测下一个 token ”或“重建”这样简单的思路会产生如此丰富的表示?

Yuandong Tian 的 X 截图
最初,世界模型的概念源于人类对理解和模拟现实世界的追求。
它与动物(包括人类)如何理解和预测周围环境的研究相关,这些研究起源于认知科学和神经科学。随着时间的推移,这一思想被引入到计算机科学、特别是人工智能领域,成为研究者设计智能系统时的一个重要考虑因素。
在人工智能领域,所谓的世界模型,是指机器对世界运作方式的理解和内部表示,也可以理解为抽象概念和感受的集合。它能帮助 AI 系统理解、学习和控制环境中发生的事情。因此世界模型也可以看作是 AI 系统的“心智模型”,是 AI 系统对自身和外部世界的认知和期望。
比如,玩家正在玩一个赛车游戏,世界模型可以协助玩家模拟赛车预测不同驾驶策略的结果,从而选择最佳的行驶路线;或者在现实中,一个机器人可以使用世界模型来预测移动一件物体可能引起的连锁反应,从而做出更安全、更有效的决策。
世界模型对于发展通用人工智能至关重要,因为它不仅提高了 AI 的抽象和预测能力,使其能够理解复杂环境并规划未来行动,还促进了 AI 的创造性问题解决和社会互动能力。通过内部模拟和推理,世界模型使 AI 能够适应新环境、有效合作以及自主学习,从而推动 AI 技术向更高层次的智能进化。
02 Meta 力推非生成式世界模型
既然 LeCun 说生成式路线的 Sora 不行,那么 Meta 发布的非生成式路线的 V-JEPA 水平如何?
去年,LeCun 提出了一个全新思路,希望“打造接近人类水平的 AI”。他指出,构建能够学习世界模型或许就是关键。
通过这种方式,机器不仅能更迅速地学习和规划解决复杂问题的策略,而且也能更有效地适应新颖或未知的环境。并且 LeCun 还断言:“掌握了如何学习和应用这种世界模型的 AI ,将能够真正地接近人类水平的智能”。
动物和人类的大脑运行着一种模拟世界的模型,这种模型在婴儿期通过观察世界就已经学会,是动物(包括人类)对周围发生情况做出良好猜测的方法。
LeCun 将这种直觉性的推理称为“常识”(包含我们对简单物理学的掌握)。他根据大脑运行机制,提出了一个端到端的仿生架构,包含 6 个核心模块:配置器、感知模块、世界模型、成本模块、参与者模块和短期记忆模块。
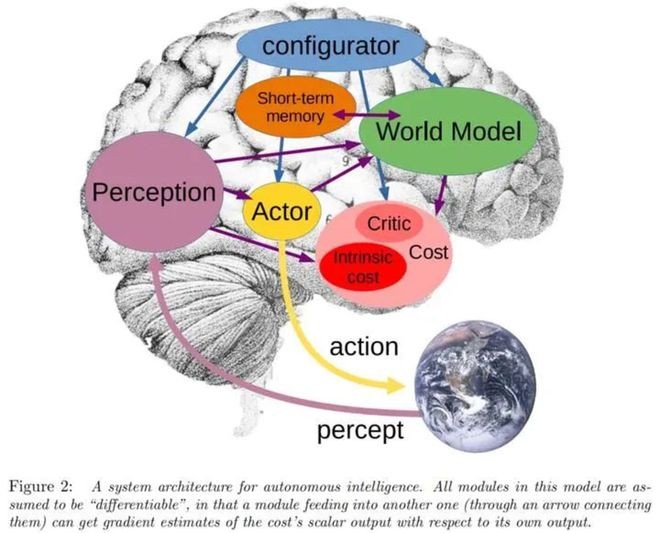
Yann LeCun的自主智能系统的架构示意图,来源:《通向自主机器智能的路径 版本0.9.2, 2022-06-27》
其中世界模型模块是最复杂的部分。它主要承担两个关键任务:一是补充感知模块未能捕获的信息;二是对世界未来状态进行预测,这不仅包括世界自然发展的趋势,还有参与者行为可能引起的变化。
简而言之,世界模型就像是一个现实世界的虚拟模拟器,它需要能够应对各种不确定性,做出多种可能的预测。
基于该理念设计的 V-JEPA 是一种“非生成模型”,通过预测抽象表示空间中视频的缺失或屏蔽部分来进行学习。
这与图像联合嵌入预测架构(I-JEPA)相似,I-JEPA 通过比较图像的抽象表示来进行学习,而不是直接对比“像素”。与尝试重建每个缺失像素的生成式方法不同,V-JEPA 摒弃了预测那些难以捉摸的信息,这种方式使其在训练和样本效率上实现了1.5到6倍的提高。
V-JEPA 采用了自我监督的学习方法,就好比一个初生儿,通过观察来理解世界,建立自己的认知。因此,Meta 完全使用未标记的数据进行预训练。标签仅用于在预训练后使模型适应特定任务。Meta 表示,这种类型的架构比以前的模型更有效,无论是在所需的标记示例数量方面,还是在学习未标记数据方面投入的总工作量方面。
V-JEPA模型的训练过程是,先遮蔽掉视频中的大部分内容,只向模型展示一小部分上下文,然后要求预测器填补缺失的部分——不是以实际像素的形式,而是在这个表示空间中以更抽象的描述来填补。
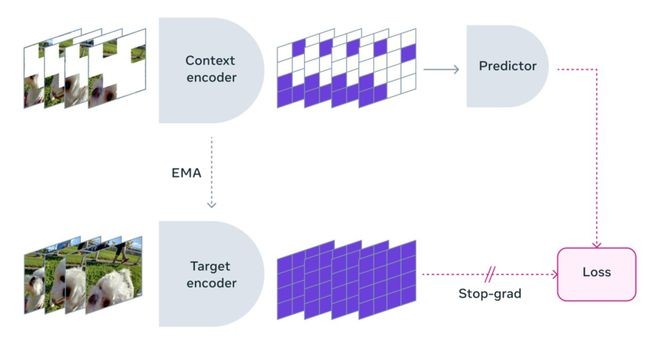
V-JEPA 通过预测学习的潜在空间中的屏蔽时空区域来训练视觉编码器,图片来自Meta。
这个过程涉及到两个核心步骤,一是掩蔽技术,二是高效预测。
V-JEPA 并未接受过理解某一特定类型操作的训练。相反,它对一系列视频进行了自我监督训练,并了解了许多有关世界如何运作的知识。Meta 团队仔细考虑了屏蔽策略——如果你不遮挡视频的大片区域,而是到处随机采样补丁,那么任务就会变得过于简单,并且模型不会学到任何关于世界的特别复杂的东西。
在抽象表示空间进行预测至关重要,因为这使得模型能够集中于视频中更高层次的概念信息,而非那些对大多数任务来说并不重要的细节。毕竟,当视频展示一棵树时,观看者通常不会对每片叶子的细微动作感兴趣。
Meta 表示,V-JEPA 是第一个擅长“冻结评估”的视频模型,只要在编码器和预测器上进行所有自监督预训练。当想让模型学习一项新技能时,只需训练一个小型轻量级专业层或在此之上训练一个小型网络,这是非常高效和快速的。
V-JEPA 中的“V”代表“视频”,它只是一个关于感知的视频模型。但 Meta 表示,正在仔细考虑将音频与视觉效果结合起来,进一步构建世界模型。
现在,Meta 已经将 V-JEPA 代码开源,供用户下载使用。而 Sora 仍然没有向普通用户开放。
不论 LeCun 是真心觉得生成式路线无法实现世界模型,还是为了让 V-JEPA 在与 Sora 的竞争中争取用户的关注度,Meta 都在用开源的方式真正实现“open 的 AI”。
这一次,V-JEPA 能否像去年的 LLama 一样,利用开源模式在大模型的竞赛中占得先机?
参考资料:
- 《Meta发布V-JEPA,世界模型更进一步,这是通往通用人工智能(AGI)之路吗?》,作者:求索,知乎。