热点-特斯拉「擎天柱」机器人视频爆了!端到端AI大脑加持,挑战高难度瑜伽

新智元报道
编辑:桃子 好困
【新智元导读】特斯拉人形机器人「擎天柱」最新视频公开,在端到端神经网络加持下,能够精准分类物体、找准身体平衡感,让众多网友惊呼将改变人类。
周末,特斯拉人形机器人「擎天柱」一波更新,引众多网友围观。
官方发布的一个视频中,「擎天柱」现在可以自主对对象进行排序。
这全凭背后的神经网络完成了端到端的训练,即「视频输入,控制输出」。

它现在能够自我精确操控手部,以及腿部的动作,更高效学习各种任务。

甚至,只利用视觉和关节位置编码器,就能够在空间中精确定位手的位置。

另外,它的神经网络完全在车载设备上运行,而且仅使用视觉能力。
在强大技术加持背后,使得「擎天柱」能够自动分类不同颜色的积木块。

即便是有人干扰,「擎天柱」也不畏惧,还在认真工作。它还有自主纠正的能力,积木倒了,拿起来再摆正。
不仅能分类积木,还能执行与之相反的动作,把积木再拿出来。

干了一天的活,再做个舒展运动。此时,「擎天柱」单腿直立,双臂伸展,有模有样。
最后双手合十「Namaste」。

看过视频的网友惊叹道,不到2年前,「擎天柱」还需要被推上舞台,而现在却能如此快速地完成表演!而且,这不是事先编好的戏法!它使用的是AGI,太神奇了 !

还有网友调侃道,看看「擎天柱」那平衡感......已经在瑜伽上打败我了。
这是2022年10月,在AI DAY上,「擎天柱」原型被三个壮汉,抬上来和大家打招呼。

马斯克曾介绍,「擎天柱」与特斯拉FSD(全自动驾驶)构建的强大视觉系统能够共通,两者的底层模块已经打通。
在他看来,特斯拉一直以来都是一家AI公司,而不仅仅是汽车公司。
「很快,我们将会看到『擎天柱』的数量,将远远超过特斯拉汽车。」

如何实现?
在今年特斯拉的股东大会上,放出了5个「擎天柱」同时向前行进的视频。

相较于与去年首次亮相的「擎天柱」,已经完成了非常大的迭代升级。
再到这次,通过视觉,精细控制手部动作,更是加满了buff。
英伟达高级科学家Jim Fan对擎天柱进行了「逆向工程」,对其技术堆栈可能实现的方式进行了分析。

值得一提的是,Jim Fan的深度分析,甚至吸引到了马斯克的回关!

1. 模仿学习
几乎可以肯定,Optimus流畅的手部动作,是基于对人类操作员的模仿学习(行为克隆)而训练出来的。
相比之下,如果采用在模拟中进行强化学习的方法,则会造成抖动的动作和不自然的手部姿势。
具体来说,有至少4种方法,可以用于收集人类的示范:
(1)定制远程操作系统:这是特斯拉团队最有可能采用的手段。
开源实例:ALOHA是斯坦福、UC伯克利和Meta开发的一种低成本的双机械臂和远程操作系统。它能实现非常精确、灵巧的动作,例如将AAA电池装入遥控器或操作隐形眼镜。

ALOHA项目地址:https://tonyzhaozh.github.io/aloha/
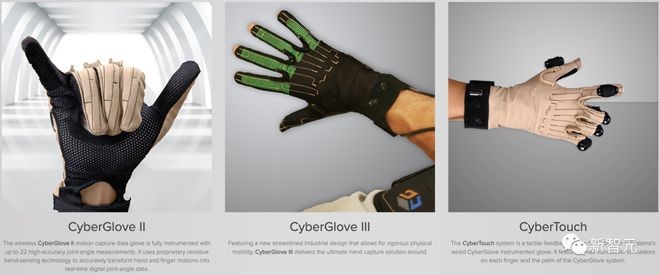
(2)动作捕捉(MoCap)方法一:利用好莱坞电影中使用的MoCap系统来捕捉手部关节的细微动作。
Optimus具有五个指头的双手是一个很好的设计策,从而可以实现直接映射——与人类操作员没有「具象化差距」。
例如,演示人员戴上CyberGlove并抓住桌上的方块。此时,CyberGlove会实时捕捉运动信号和触觉反馈,并将其重新定向到Optimus上。
(3)动作捕捉(MoCap)方法二:通过计算机视觉技术。
英伟达的DexPilot可以实现少标注、无手套的数据采集,人类操作员只用自己的双手即可完成任务。
其中,4个英特尔RealSense深度摄像头和2个英伟达Titan XP GPU(是的,这是2019年的工作),可以将像素转化为精确的运动信号,供机器人学习。
英伟达官方演示中,DexPilot系统加持下的机器人手臂,能够精准完成抓握、放置任务。

(4)VR头显:将训练室变成VR游戏,让人类「扮演」Optimus。
使用原生VR控制器或CyberGlove来控制虚拟Optimus的双手,可以带来远程数据收集的优势——来自世界各地的标注人员可以在不到现场的情况下做出贡献。
比如,Jim Fan参与的iGibson家庭机器人模拟器等研究项目,就有类似的VR演示技术。

iGibson项目地址:https://svl.stanford.edu/igibson/
以上4种并不相互排斥,Optimus可以根据不同的场景进行组合使用。
2. 神经架构
Optimus是端到端训练的:输入视频,输出动作。
可以肯定,这是一个多模态Transformer,其中包含以下组件:
(1)图像:高效的ViT变体,或者只是旧的ResNet/EfficientNet骨干网络。块的取放演示不需要复杂的视觉技术。图像骨干的空间特征图可以很容易地进行分词。

EfficientNet论文地址:https://arxiv.org/abs/1905.11946
(2)视频:两种方法。要么将视频压缩成一系列图像并独立生成token,要么使用视频级的分词器。
高效处理视频像素卷的方法有很多。你不一定需要Transformer骨干网络,例如SlowFast Network和RubiksNet。

SlowFast Network论文地址:https://arxiv.org/abs/1812.03982
RubiksNet项目地址:https://stanfordvl.github.io/rubiksnet-site/
(3)语言:目前还不清楚Optimus是否支持语言提示。如果是的话,就需要一种将语言表征与感知进行「融合」的方法。
比如,轻量级神经网络模块FiLM,就可以实现这个目的。你可以直观地将其视为语言嵌入图像处理神经通路中的「交叉注意力」。

FiLM论文地址:https://arxiv.org/abs/1709.07871
(4)动作分词:Optimus需要将连续运动信号转换为离散的token,从而使自回归Transformer能够正常工作。
- 直接将每个手关节控制的连续值分配到不同的区间。[0,0.01)->token#0,[0.01,0.02)->token#1,等等。这种方法简单明了,但由于序列长度较长,效率可能不高。
- 关节运动彼此高度依赖,这意味着它们占据了一个低维的「状态空间」。将VQVAE应用于运动数据,可获得长度更短的压缩token集合。
(5)将上述部分组合在一起,我们就有了一个Transformer控制器,它消耗视频token(可选择性地通过语言进行微调),并一步一步地输出动作token。
表格中的下一帧画面会反馈给Transformer控制器,这样它就知道了自己动作的结果。这就是演示中展示的自我纠正能力。
其结构与谷歌的RT-1和英伟达的VIMA会比较相似:
Google RT-1:https://blog.research.google/2022/12/rt-1-robotics-transformer-for-real.html?m=1
NVIDIA VIMA:https://vimalabs.github.io
3. 硬件质量
正如前面提到的,紧跟人类形态是一个非常明智的决定,这样在模仿人类时就没有任何差距了。
从长远来看,相比于波士顿动力简陋的手部,Optimus具有五根手指的的双手,将会在日常工作中表现得更加出色。
FSD是前菜,擎天柱才是未来
还有一位网友对特斯拉人形机器人的升级,感慨道「这将永远改变世界」。
在接下来的长文中, 他分析了擎天柱的技术升级,还有未来憧憬。

2021年8月19日,特斯拉首次向世界,展示了将要推出的一款人形机器人「Optimus Bot」。
当场现身跳舞的只是穿着机器人演出套装的人类。

然后,马斯克进行了10分钟的演示,概述了将产品阵容扩展到人形机器人的计划。

时间快进到现在,特斯拉已经造出多个可用的机器人原型。
它们能够自主行走、拾取、放置物体、周围环境导航,以及执行排序等任务。

最新视频中,擎天柱已经能够完成积木分类。
乍一看,可能不会令人印象深刻,特别是当你将它与波士顿动力的机器人Artemis进行后空翻和跑酷相比时。

但它「如何学会排序」是我想要关注的突破,这不仅对特斯拉,而且对全球劳动力市场都具有令人兴奋的影响。
「视频输入,控制输出。」
这是马斯克已经谈论了很长一段时间的主题。前提是构建一个神经网络系统,不需要人类编写告诉机器做什么的代码。
而且,这套原理与特斯拉自动驾驶系统FSD相通。
前段时间,马斯克直播试驾FSD v12时,自豪地介绍背后神经网络的训练,全部使用的视频数据,任务执行的能力,不需要手写一行代码。

特斯拉总部有一个「AI大脑」,可以分析汽车收集的大量视频数据,然后告诉汽车如何在道路上遇到的每个场景中行走。
特斯拉FSD没有一行人类编写代码来解释停车标志、交通信号灯等,而是通过AI学会了如何通过观察驾驶的情况来做到这一点。

这的确是一件大事。
这意味着,特斯拉现在受限于,可以从其电动汽车驾驶中收集多少视频数据,以及有多少芯片(来自英伟达H100及和内部DOJO芯片)来处理这些数据。
好在,他们不再受到「代码」突破的限制,所拥有的AI大脑,可以通过足够的例子来解决这个问题。

更重要的是,这种解决现实世界驾驶问题的方法可以应用于任何物理任务。
只需要输入视频,AI就会发出控制信号。于是,「擎天柱」机器人才是真正的未来。
即使「擎天柱」和特斯拉汽车看起来像是两个完全不同的物体,但它们的共同点比看上去要多得多。
它们都使用软件来导航其环境的物理对象,使用相同的车载计算机来处理所述软件,使用相同的电池为电机供电,使每个物体都能移动,使用人工智能大脑,通过分析无数视频数据来自学如何执行任务。

根据特斯拉迄今为止公布的信息,可以安全地假设机器人能够做到这一点,不是因为人类编写的代码「拿起蓝色块,放入蓝色区域」......
但通过分析按适当颜色排序的块的视频片段,这与汽车学习自动驾驶的方式没有什么不同。
一个看似不起眼的动作凸显了这一点,但却证明了这种方法有多么强大。
包括后面片段中,「擎天柱」摆正了侧倒出的积木。这可能意味着AI大脑拥有的视频片段显示,物体被正面朝上分类,而不是侧面朝上。
机器人无需人类代码即可自动理解它所排序的块落在其一侧,将其拾起,调整方向,然后将其放回正确的一侧。
这意味着机器人能够动态调整,无需任何关于如何处理现实世界的复杂性的明确指示。
只要特斯拉能够制造出一种能够从物理角度可靠地执行命令的机器人。这意味着执行器、电池、手、关节等都被制造得极其耐用并且能够重复处理任务。
世界将永远被改变。
凭借足够的力量和灵活性,特斯拉的机器人只需观看人们执行上述任务的视频片段,就可以处理几乎所有的体力任务。

拿起吸尘器并在房子里运行、分类折叠衣物、收拾屋子、将物料从A点移动到B点、捡起垃圾并将其放入垃圾箱、推着割草机、监控某个区域是否存在安全相关问题、砌砖、锤击钉子、使用电动工具、清洗盘子……
与汽车一样,机器人在处理上述任务时不受代码突破的限制。
它受限于特斯拉AI大脑可以处理的视频数据和芯片数量的限制,来告诉机器人该做什么。
现在,凭借「擎天柱」,特斯拉开始转型为世界上绝大多数人认为,需要几十年甚至几千年才能实现的产品类别。但事实上,该公司正在敲响范式转变的大门,这可能会颠覆工作的意义。
在最新的「马斯克传」中,摘录了马斯克和他的工程师之间的讨论。
「机器人的目标应该是在不充电的情况下运行16小时。」这相当于2个8小时轮班的人力劳动,而且完全不间断。
它极大地降低了劳动力成本,使产品和服务的预算可能只是现在的一小部分。而且它让企业没有理由在5年内以7倍的成本来雇用一个人来生产产品和服务,做同样的工作。

现实是,这个未来比许多人想象的要近得多。
特斯拉似乎已经解决了人类劳动中最困难的问题——AI大脑将根据在现实世界中分析的视频自动生成动作。
凭借其制造专业知识,他们应该能够在未来几十年内,每年生产数百万个这样的产品,这应该会带来巨大的丰富。
参考资料:
https://twitter.com/Tesla_Optimus/status/1705728820693668189
https://twitter.com/DrJimFan/status/1705982525825503282
https://twitter.com/farzyness/status/1706006003135779299