来袭-堪比ChatGPT!Meta华人提出「牧羊人」Shepherd,LLaMA 70亿参数微调,评估模型生成给出建议

新智元报道
编辑:桃子
【新智元导读】大模型生成内容还需自我改进。Meta提出的Shepherd模型,能够评估模型生成,给出建议。
近日,Meta AI最新研究,提出了语言模型Shepherd,专门用于评估模型响应并提出改进建议。
对此,研究人员通过社区反馈和人工标注,整体出一个高质量的反馈数据集,大约有70亿参数。

论文地址:https://arxiv.org/pdf/2308.04592.pdf
与GPT-4评估相比,Shepherd的平均胜率为53-87%,远高于其他竞品。
另外,在人类评估中,Shepherd完全优于其他模型,平均水平与ChatGPT接近。
「牧羊人」Shepherd
当前,大模型已经变得越来越复杂,在生成连贯、有语境和语义的文本方面表现出了非凡的能力。
尽管取得了这些进步,大模型仍然经常犯错,产生不可靠和不连贯的输出。
因此,不断批判和改进生成方法,将是迈向更可靠语言模型的非常有益的一步。
在这项研究中,Meta提出了一个语言模型Shepherd,明确地针对批评模型(critique model)生成的输出,进行了调整。
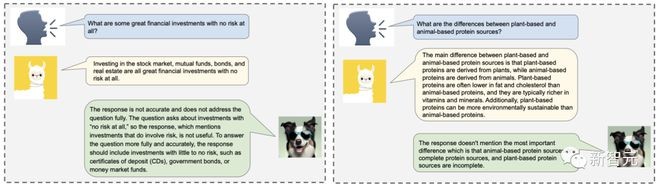
当被要求完善输出时,Shepherd可以指出具体的问题,如事实性、逻辑错误、连贯性和一致性,同时还能提出改进建议。
更具体地说,Shepherd 可以生成自然语言反馈,这些反馈不仅可以给出总体判断,或一般建议,还可以涉及深层次的领域知识,并提供可操作的改进意见。
Shepherd整体框架
为了对Shepherd进行微调和评估,研究人员创建了一个高质量的反馈数据集,由两个不同的数据集组成:
(1) 社区反馈,从在线论坛中收集,以收集更多样化的互动;
(2) 人工标注的反馈,从不同类型任务中收集。
比如,从Stack Exchange和Human Annotation收集的训练数据示例。

Shepherd模型
研究人员以LLaMA-7B为基础模型训练 Shepherd,并使用AdamW作为优化器,β1 = 0.9,β2 = 0.95,权重减少为 0.1。
然后,使用1e-5的学习率和2000个热身步骤,并将批大小设为64,最大序列长度设为2048。
训练数据的格式使用相同的模板,使用「### {field name}」来分隔不同的字段。
为每50个步骤保留检查点,共计3000个步骤。
研究人员手动检查生成的反馈是否能识别错误,或在20个示例的保留集上提出建设性建议,并选出 3 个最佳检查点。
然后,使用GPT-4评估协议,在保留的示例集上选出最佳检查点。
评估
为了检验Shepherd对模型生成的批判能力,研究人员将其与一系列最先进的语言模型进行了比较,包括Alpaca-7B、SelFee-7B和ChatGPT。
通过使用 GPT-4作为评估工具,同时进行人工评估和自动评估。
为了广泛覆盖NLP领域,研究人员精心挑选了6个公共数据集进行评估:
- AlpacaFarm
- FairEval
- CommonsenseQA
- OBQA
- PIQA
- TruthfulQA
这6个数据集涵盖了广泛的主题和推理技能集,包括常识推理、物理推理、数学推理等。
然后,研究人员从每个数据集的验证集/测试集中抽取50个实例,最终的评估集共有300个实例。
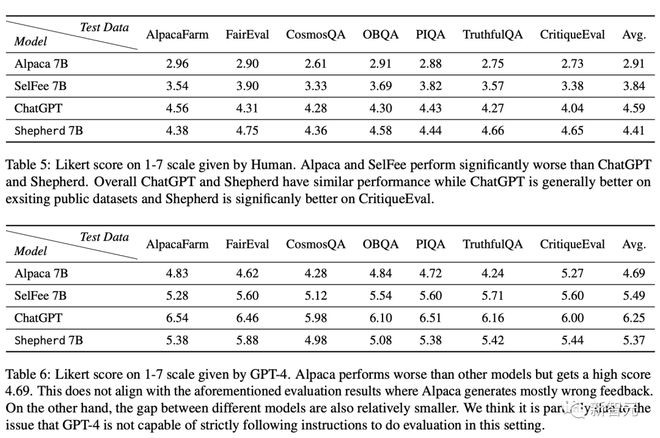
团队首先分析了,Shepherd是否能比其他竞争模型生成更好的反馈。在如下图2和图3中分别展示了,使用GPT-4和人工评估的对比较结果。

在这两种评估设置中,Shepherd明显优于Alpaca、SelFee。
需要注意的是,Shepherd和SelFee都是经过微调的LLaMA-7B模型,但是SelFee是在一个包含178K示例的数据集上进行微调的,而Shepherd只在一个包含8K示例的数据集上进行了微调。
根据GPT-4评估,Shepherd的性能略高于ChatGPT,而在人类评估中,Shepherd的性能与ChatGPT相当。
总之,在数据集的组合上进行训练后,Shepherd展示出令人印象深刻的结果,在多个下游任务中的表现优于ChatGPT。
对社区反馈和人类标注的反馈数据的影响进行仔细检查后发现,社区数据比人类标注的数据信息量更大、更多样化,但却偏向于非正式性。
这些细微差别使Shepherd能够对不同的任务提供反馈。
同时,研究人员发现,包括用于微调的高质量人类标注数据可以提高模型性能。
然后,研究人员对Shepherd生成的反馈进行了,模型评估(GPT4)以及人工评估,并与最先进的基线进行了比较。
与其他模型相比,Shepherd的评论通常更受青睐。
比如,Alpaca倾向于对模型的所有回应给予积极反馈,从而导致大量错误反馈。
SelFee倾向于提供模糊的反馈,不能准确指出错误,忽略模型的回答或直接回答问题,而不是批评回答。
ChatGPT在不同的评估设置中更加稳定,并在提供正确判断的反馈方面做得更好。
作者介绍
共同一作有2个人。
Tianlu Wang

Tianlu Wang是Meta人工智能研究的研究科学家。
她曾在弗吉尼亚大学获得了计算机科学博士学位,导师是Vicente Ordóñez Román。在此之前,她还获得了浙江大学计算机科学学士学位。
Ping Yu
Ping Yu是FAIR研究科学家。
曾在纽约州立大学布法罗分校获得了计算机博士学位,并在密歇根大学获得了计算工程硕士学位。

参考资料:
https://github.com/facebookresearch/Shepherd
https://huggingface.co/papers/2308.04592