电讯-Yann LeCun朝“世界模型”理论迈一步,Meta开源“像人一样学习”的图像模型 | 最前线
文 | 周鑫雨
编辑 | 苏建勋
六根手指、机器猫圆手……手部细节一直是图像生成式AI的盲区。

用Midjourney生成的图,手部有6根手指。
而如今,这一图像生成的阿喀琉斯之踵有望被Meta破解。6月14日,Meta 推出了I-JEPA(Image Joint Embedding Predictive Architecture, 图像联合嵌入预测架构),实现无需手动变换图像对额外知识进行编码的情况下,生成基于世界常识的图像。
这一研究由纽约计算量子物理中心研究院Anna Dawid,以及图灵奖获得者Yann LeCun共同提出——I-JEPA也被视作继LeCun提出“世界模型(World Model)”构想后,第一个卓有成效的进展。
从自回归到世界模型
为何图像生成模型普遍难以精确生成手部?其根本原因在于以自回归为框架的模型缺乏对现实世界的常识。
在自回归框架下,模型利用当前的上文信息对下文信息进行预测。应用至图像生成领域,“图像像素”则成了上下文信息:自回归模型通过将训练图像转换为一维序列输入,利用Transformer转换器自回归预测图像像素。
这一方法的优势在于可以很好地建立像素和高级别属性,如纹理、语义和尺寸等属性之间的关系。但劣势依然明显,由于缺乏常识,模型对图像像素的预测时常违反常理,比如“六根手指”——这也造成了自回归模型常出现的“幻觉”现象。
LeCun认为,想要让AI接近人类水平,其需要像婴儿一样学习世界如何运作。由此,他提出了“世界模型”的概念,解决方案即为JEPA(联合嵌入预测架构)。
JEPA通过一系列的编码器提取世界状态的抽象表示,并使用不同层次的世界模型预测器,来预测世界的不同状态,并在不同的时间尺度上做出预测。
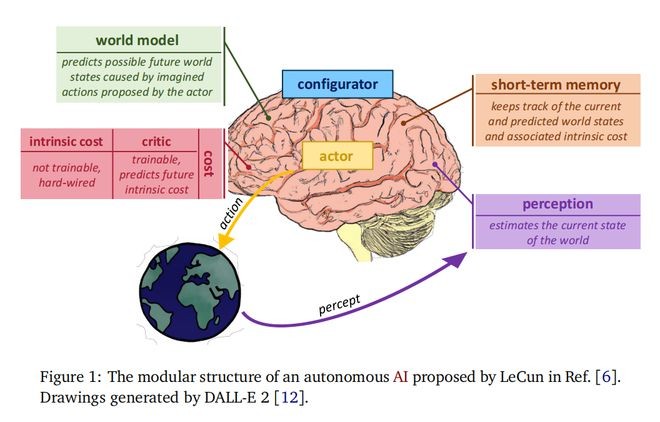
LeCun在论文中提出的基于“世界模型”的自主化AI的模块化结构。图源:论文
在智源大会的演讲中,LeCun有关“层级规划”举了一个例子:我想从纽约前往北京,第一件事是去机场,第二件事是乘去往北京的飞机,最终的代价函数(cost function)可以表示从纽约到北京的距离。那么我该如何去机场?解决方案是把任务分解到毫秒级,通过毫秒级的控制来找到预测成本最小的行动序列。
LeCun表示,所有复杂的任务都可以通过这种“分层”的方式完成,而层次规划则是其中最大的挑战。
迈向“世界模型”的第一步
为何说I-JEPA是迈向“世界模型”的一步?
从训练原理来看,I-JEPA预测的并非是图像像素,而是抽象的预测目标。其中的预测器能够从部分可观察的上下文中,对静态图像中缺失的空间进行模拟。

基于图像的联合嵌入预测体系结构:使用单个上下文块来预测来自同一图像的各种目标块。图源:论文

I-JEPA训练过程:给定一张图像,从中随机抽取4个目标块,比例范围为(0.15,0.2),宽高比范围为(0.75,1.5)。接下来,随机采样一个范围为(0.85,1.0)的上下文块,并删除任何重叠的目标块。在这种策略下,目标块是相对语义化的,而上下文块在保证信息量足够大的同时又很稀疏(处理效率高)。图源:论文
为了理解可观察的内容,Meta训练了一个随机解码器和生成模型,将I-JEPA预测的内容映射为像素,再输出为预测的内容草图。

I-JEPA预测器可以正确地捕捉空间的不确定性,并正确生成预测对象的部件(例如,鸟的背部和汽车的顶部)。图源:论文
从效果而言,I-JEPA的计算效率远高于主流计算机视觉模型。比如Meta在72小时内用了16块A100训练了一个参数规模为632M的视觉Transformer模型,所用GPU小时数是一般方法的1/10到1/2,并且在相同训练数据量下,误差率更低。
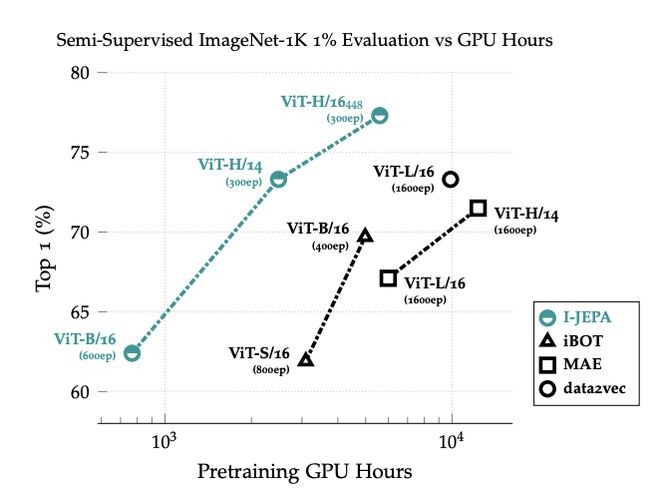
与以前的方法相比,I-JEPA所需的计算量更少,性能更强:与MAE和data2vec相比,I-JEPA所需的预训练时间更少。与iBOT相比,I-JEPA所需的手动标注的数据更少。与此同时,最大的I-JEPA模型(ViT-H/14)比其他两款中最小的模型(ViT-H/16)所需的计算更少。图源:论文
I-JEPA已经显示出世界模型在图像生成上的作用。可预见的是,JEPA在视频、音频等更多模态的预测和生成中将发挥作用。目前,I-JEPA的训练代码和模型检查点已在GitHub上开源。
I-JEPA论文链接:https://arxiv.org/pdf/2301.08243.pdf
JEPA原理解释论文链接:https://arxiv.org/abs/2306.02572
GitHub链接:https://t.co/DgS9XiwnMz
欢迎交流