内部-媲美Gen-2,Meta多模态创AI生图新里程碑!破文生视频历史难题,静图秒变视频逼真到炸裂

新智元报道
编辑:编辑部
【新智元导读】文生视频,直接被革命了!Meta连发两个重磅研究,多模态模型Emu的变体 Emu Video和Emu Edit联动解锁生成式AI未来。
就在刚刚,Meta一连解锁两个重磅研究,生成式AI,再次到达全新的里程碑!
Emu Video,是一种基于扩散模型的文本到视频生成方法,可以分解步骤生成高质量的视频。

论文地址:https://emu-video.metademolab.com/assets/emu_video.pdf
经过Emu Video处理过的视频,具有高度的风格化,当图像动起来、添加运动之后,一切变得如此栩栩如生。
兔子手中忽然就变出一只小号,然后开始开心地跳舞,然后小号变成了彩虹色,兔子开始随着音乐惬意地慢摇。

下一秒,兔子就戴上了VR眼镜,在夏威夷的海岛上散步,然后开始跳起草裙舞,又变身DJ、粉色金发娃娃……

Emu Edit,可以仅仅基于文本指令就对图像进行编辑,通过识别和生成任务,编辑得格外精确。

论文地址:https://emu-edit.metademolab.com/assets/emu_edit.pdf
Emu Edit对于指令遵循得如此精准,以至于能确保输入图像中与指令无关的像素保持不变。
比如,让一杯橙汁出现在游泳池边,它立马完美地瞬移了。

我们还可以让这杯橙汁变成一个金色的高脚杯,背景还可以瞬穿到文艺复兴时期。

网友惊呼,这简直是AI生图的下一个里程碑!

Emu Video:高质量视频生成「分解法」
目前,视频生成中最主流的方式,就是使用扩散模型一次性生成所有的帧。
而与之形成鲜明对比的是,在NLP中,长序列生成被表述为一个自回归问题——根据先前预测的单词来预测下一个单词。这样,每个后续预测的调节信号就逐渐变强。
由于视频本质上是时间序列,因此可以假设加强调节信号对于高质量的视频生成也很重要。

An Emu on a ski trip, 4k, high resolution
但这其中就有一个问题:使用扩散模型的自回归解码很有挑战性,因为从此类模型生成单个帧,本身就需要多次迭代。
Meta研究者想到的办法是,将文本到视频的生成分解为两个子问题——
1. 根据输入文本提示生成图像; 2. 基于图像和文本的更强条件生成视频。
为模型提供起始图像和文本的方法,就让视频生成变得更容易了,因为模型需要做的,只是预测图像未来将如何演变。
这种「分解」的视频生成方法,可以有效地训练模型,并且可以通过单个扩散模型来实现。
基于Emu模型,Meta团队提出了一种基于扩散模型的T2V生成的简单方法——Emu Video。
这是一种用于视频生成任务的统一架构,可对各种输入做出响应:文本、图像,以及文本和图像。

由于视频文本数据集比图像文本数据集小得多,因此研究者还使用了权重保持冻结的预训练文本到图像(T2I)模型来初始化分解文本到视频模型。
其中最关键的设计决策,就是调整视频扩散的噪声时间表,以及让我们直接生成更高分辨率视频的多阶段训练。

分解文本到视频的生成,首先要生成以文本p为条件的图像I,然后使用更强的条件(生成的图像和文本)来生成视频V。为了在图像上条件化模型F,研究者对图像进行了临时的零填充,并将其与二进制掩码连接起来,指示哪些帧是零填充,哪些是噪声输入
与直接的T2V方法不同,在推理时,Meta的分解法能够显式生成图像,这就能够轻松地保留文本到图像模型的视觉多样性、风格和质量。

Emu Video可以生成高质量且时间一致的视频,同时使用文本提示作为输入 (顶部两行)或用户提供的附加图像(底部行)
这使得Emu Video的性能优于直接的T2V方法,即使在考虑相同数量的训练数据、计算和可训练参数时,也是如此。
大多数先前的工作,都是通过利用T2I模型来解决T2V生成问题。比如,有几项工作是采用免训练方法,通过在T2I模型中注入运动信息,来生成零样本的T2V。
虽然这些方法不需要或需要有限的训练,但生成的视频的质量和多样性,都是有限的。
与之前需要深度串联多个模型的工作不同(比如用于Make-A-Video的5个模型),新方法仅使用2个扩散模型,能够以每秒16帧的速度,生成512x512的4秒长视频。

实验
研究者在3400万个许可视频文本对的数据集上,训练了Emu Video。
视频时长从5秒到60秒不等,涵盖了各种自然世界概念。
这些视频不是针对任何特定任务而策划的,也没有针对任何文本框架相似性或美观性进行过滤。
研究者使用了之前工作中的文本提示集来生成视频。
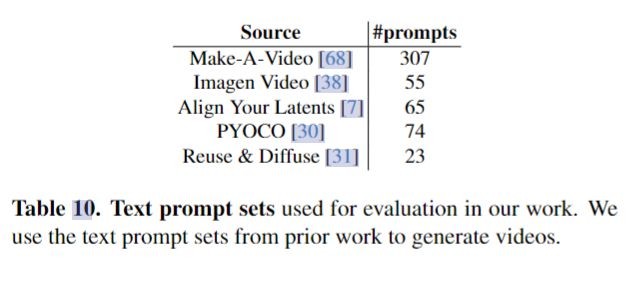
这些提示涵盖了各种各样的类别,可以测试模型生成自然和梦幻视频以及组成不同视觉概念的能力。
然后,研究者会使用JUICE评估方案进行可靠的人工评估,并使用5名评估者的多数票,每次都进行比较。

该表反映了Emu Video中的关键设计决策。每个表都显示了采用设计决策与不采用设计决策的模型在质量(Q) 和忠实度(F)方面的偏好
Emu Video中的设计选择如下。
第一行是直接从文本到视频生成的视频,结果的视觉质量低,且不一致。
第二行是使用分解的文本到视频方法,这种方法生成的视频质量高,一致性也得到了提高。
第三行是在512px生成时,不使用零终端SNR噪声计划,这会导致各代图像之间出现明显的不一致。
第四行是使用HQ数据微调第二行的模型,来增加生成视频中的运动。

另外,通过小的架构修改,研究者还在T帧上调节了模型,并且进行了扩展。
他们训练了Emu Video的变体,生成了以「过去」的16帧为条件的未来16帧。
对于两个不同的未来提示,模型会生成合理的扩展模型,既尊重原始视频,也尊重未来文本。

效果拔群
在人工评估中,与以前的工作相比,Emu Video的视频生成更受欢迎——有趣的是,不同的受访者偏重不同,其中96%的人更看重视频质量,85%的人更看重视频对文本提示的忠实度。

与Imagen Video和Align Your Latents相比,Emu Video在风格和一致性方面,质量都更高
由于不再需要像之前的工作那样深度串联多个模型,Emu Video产出的视频质量和分辨率都极高,在人工评估中已经接近许多成功的生成式AI视频工具。
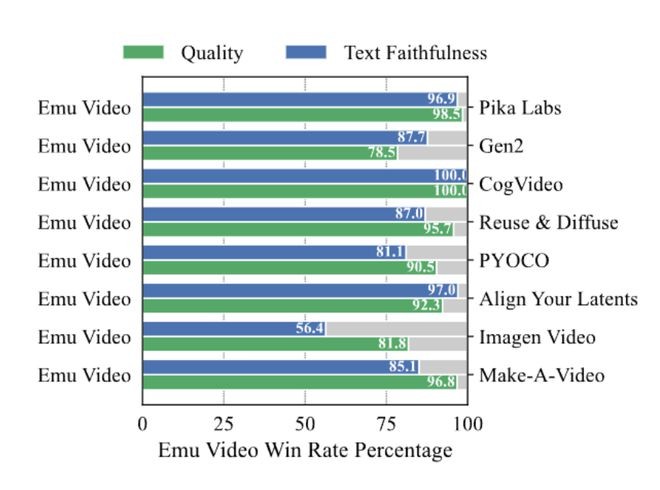
比起谷歌的Imagen,比分是81:100;比起英伟达的PYOCO,比分是91:100;比起的Meta的Make-A-Video,比分是96:100。
比起Runway的Gen-2和Pika Labs,Emu Video的表现仍然很强劲。
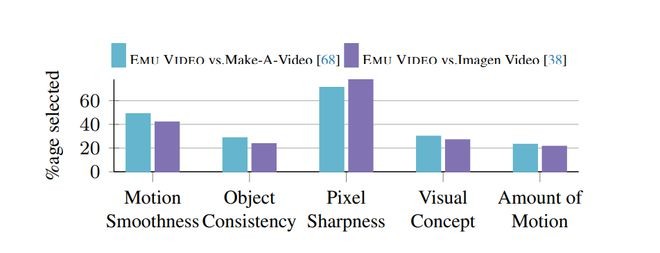
在质量方面,Emu 胜过了VideoMake-A-Video或Imagen Video。原因主要是人们更喜欢它的像素清晰度和运动平滑度
最后,同一模型可以根据文本提示,对用户提供的图像进行「动画化」,再次刷新SOTA。
一些演示

two sloths are playing chess in slow motion, 4k, high resolution

A supernova explosion in space

A clear wine glass with turquoise-colored waves inside it

A robot dj is playing the turntable, in heavy raining futuristic tokyo rooftop cyberpunk night, sci-fi, fantasy, intricate, elegant, neon light, highly detailed, concept art, soft light, smooth, sharp focus, illustration

A phoenix flying over an active volcano in Iceland, photorealistic

一个场景转换多种动作、多种场景

柯基转换成浣熊、熊猫的多种形象

不同风格的熊猫
Emu Edit:高精度图像编辑
基于指令进行图像编辑的模型,已经屡见不鲜。
然而,当前像InstructPix2Pix在内等模型能够处理任何给定的指令,但仍无法准确地去解释和执行这些指令。
可见,它们的泛化能力是有限的,有时无法完成与训练时有偏差的任务。

对此,Meta研究人员提出了Emu Edit——首个在广泛、多样的任务集上经过训练的图像编辑模型,包括图像编辑和计算机视觉任务。
Emu Edit强大之处在于,它能够通过指令进行自由格式编辑。
比如,擦除绿草坪中的小狗,再添加一个放置在红色长椅上的笔记本,然后还可以将草坪背景变成沙漠。

Emu Edit还可以将抱枕的情绪从微笑,替换成困惑,甚至还可以「检测面部」。

香蕉拿着的吉他,立马变成了冲浪板,然后就来到幻想世界,戴上了蓝手套。

小老鼠戴上了小丑帽,然后变成了一只面无表情的熊猫,接着又变成一只兴奋大笑的熊猫。

总而言之,Emu Edit能够做到对图像局部和全局的编辑、删除和添加背景、颜色和几何变换、检测和分割等任务。
实现了一键可以处理各种图像任务,并且还能高精度生成。
当前的研究方法,通常倾向于过度修改,或在各种编辑任务上表现不佳。Meta认为,图像编辑的主要目标不应该只是制作一个「可信」的形象。
相反,模型应专注于仅精确更改与编辑请求相关的像素。
与当今许多生成式AI模型不同,Emu Edit精确地遵循指令,确保输入图像中与指令无关的像素保持不变。

Emu Edit是多任务模型,它结合了各种编辑和视觉任务来进行精确的图像编辑
例如,在棒球帽上添加文字「Aloha!」时,棒球帽本身应保持不变。
研究人员认为,将CV任务作为图像生成模型的指令,可为图像生成和编辑提供前所未有的控制。
为了训练模型,Meta团队开发了一个包含1000万个合成样本的数据集,每个样本都包括输入图像、文本指令、目标图像、任务索引。
如下,是所有数据样本的分布,由任务组成主要分为三大类:基于区域的编辑、自由格式的编辑、视觉任务,细分为16个任务。
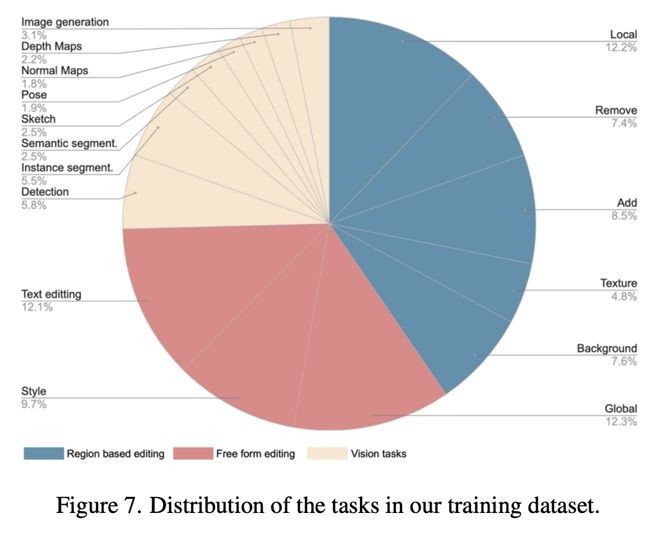
由于Emu Edit是针对各种任务进行训练的,其中最重要一点是,能够根据用户指令识别需要应用的语义编辑,如全局/局部/纹理。
但是,如果指令非常特殊(图4中的「修复缓冲器」),或者编辑类型含糊不清(图4中「将天空改为灰色」既可解释为全局编辑,也可解释为纹理编辑),模型在确定预期的编辑类型时可能会遇到困难。

为了给模型提供一个强有力的条件,来引导生成过程走向正确的任务,Meta提出为每个任务学习一个独特的嵌入任务,并将其集成到模型中。
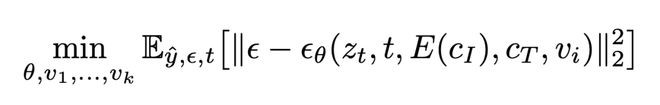
在训练过程中,任务嵌入与模型权重一起学习。
后期训练,Emu Edit能够通过少样本学习新的任务嵌入来适应新的任务,使模型的其余部分处于冻结状态。
最后,研究人员还发现,在多轮编辑场景中,重复应用模型,聚合重建和数值误差,从而产生明显的人工痕迹。
为了缓解这一问题,研究人员在每一轮编辑后,增加了一个按像素阈值处理的步骤,进而保持生成图像的质量。
实验
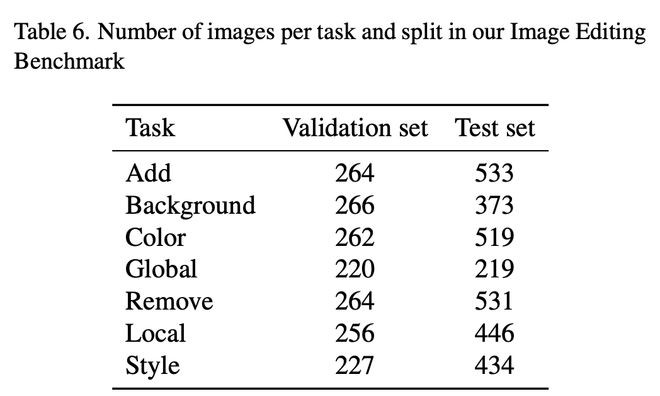
1. Emu Edit基准
研究人员比较了MagicBrush测试集和Emu Edit基准测试的结果。
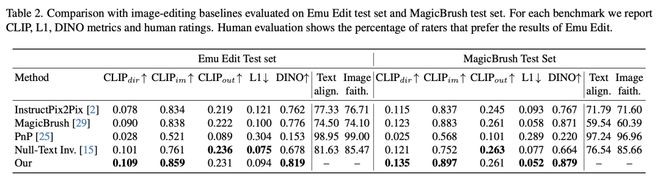
与在Emu Edit测试集和MagicBrush测试集上评估的图像编辑基线的比较
为了收集具有较低偏差和较高多样性的数据集,研究人员采用了不同的方法。
他们首先定义了7种不同类型的潜在图像编辑操作:背景修改(背景)、全局图像修改(全局)、样式修改(样式)、对象移除(移除)、对象添加(添加)、局部修改(局部)和颜色/纹理修改(纹理)。
然后,利用来自MagicBrush基准的各种输入图像集,对于每个编辑操作,让工作者设计相关的、创造性的和具有挑战性的说明。此外,为了提高所收集样本的质量,Meta还采用了验证后阶段。
2. 基线比较
研究人员将Emu Edit模型与两个基于指令的图像编辑基线模型进行比较:InstructPix2Pix和Mag-icBrush。
结果表明,与所有基线相比,人类评估者一致地喜欢Emu Edit。
此外,除了空文本反转(Null-Text Inversion)在推理过程中使用了ground-truth字幕外,Emu Edit方法明显优于现有基线,

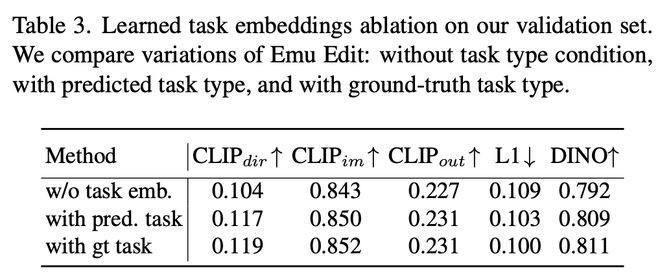
3. 消融研究
- 计算机视觉任务增强图像编辑任务
这部分,Meta团队演示了视觉任务对图像编辑任务中Emu Edit性能的重要性。
为此,研究人员训练了两个额外的模型的所有任务,除了「检测和分割」任务,和「图像到图像翻译」任务。
如下表4,增加的「检测和分割任务」提高了基于局部编辑任务中的模型性能。
此外,他们还观察到图像到图像的翻译任务,提高了自由形式编辑任务的性能。

- 学习任务嵌入的贡献
研究人员比较了Emu Edit的三种变体:(i) 以ground-truth任务嵌入为条件;(ii) 以任务嵌入为条件 (iii) 不以任务类型为条件。
表3显示了基准验证集的结果。可以看出,对任务类型进行调节,可以提高模型的性能。此外,任务预测器缩小了与ground-truth条件模型的差距。
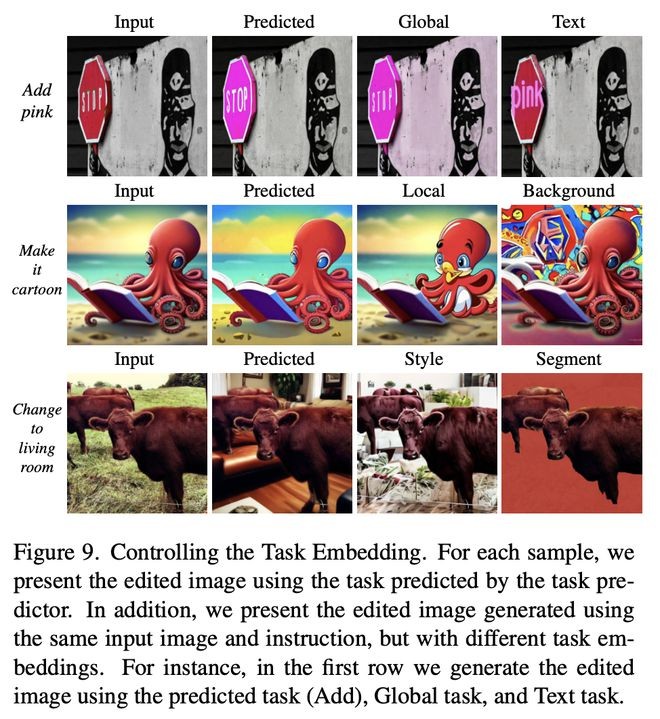
在图9中,展示了在指令和输入图像保持不变的情况下,对任务进行调整的效果。可以看出,改变任务嵌入会直接影响模型执行的任务。
4. 少样本学习新任务
研究中,Meta还通过任务反转来探索,Emu Edit对未知任务泛化。
在此过程中,保持模型权重不变,仅更新任务嵌入以适应新任务。
实验证明,Emu Edit可以迅速适应新任务,如超分辨率、轮廓检测等。当标注样本有限或计算资源有限时,Emu Edit的任务逆向适应有着巨大的优势。

虽然Meta目前的工作还仅仅是基础研究,但其潜在的应用场景可以预见。
想象一下,聊天时即时生成动画贴纸、GIF,不用再去搜索表情包,又或者编辑自己的照片或图像,不需要任何技能,就能搞定。

发个生活动态,可以将你的静态图动态化,能吸引不少人前看。
不过,Emu Video和Emu Edit虽不能替代专业艺术家和动画师,但它们可以帮助人们以一种全新的方式表达自己。
参考资料:
https://ai.meta.com/blog/emu-text-to-video-generation-image-editing-research/
https://emu-video.metademolab.com/
https://emu-edit.metademolab.com/